Gemini AI Console 新功能上線!Jupyter to Job 讓 GPU 資源管理更進化!
最近幾年,更是因為AI領域的需求大爆炸,無論在產、官、學界,幾乎是人人都在講AI的時代。從許多的 AI 模型理論,到機器學習、深度學習,或者是MLOps自動化流程,各式各樣能讓 AI 壯大的理論或工具,如雨後春筍般的出現。就當大家都在一股腦地投入 AI 領域時,底層 GPU 資源管理成了重要的基礎建設問題,這邊就分為三個部分來探討:
問題一:運算環境資源分散
第一個要討論的就是『環境』。所謂的環境就是電腦的運算資源加上AI領域所需要的軟體應用。在 AI 相關領域,光是在模型訓練階段所需要的運算能力,已經不再是 CPU 所能負擔的,因此利用 GPU 圖形顯示卡來進行模型訓練,已成為主流。
有些看倌可能會說,在台灣,硬體資源是最容易取得的地方。是的,我所看到的現象也是如此,但就是這個原因,造成了第一個問題,資源分散。曾經聽到客戶說,GPU資源不夠的話,就添購新的機器就好了,資源不夠就買,各部門都可能有設備,導致設備散在各地,很難互相支援,遇到大型專案時,就陷入尷尬的境地,要買也買不了,不買又難以將分散的資源整合。
問題二:環境建置複雜且衝突
AI 領域裡,有許多的資料科學家,他們能夠很專注在模型的開發、調校、優化等等,但是他們卻不一定能熟悉開發環境的建置。
比如說作業系統、GPU驅動、CUDA、AI 框架等等。當資料科學家被分配到設備時,第一步的環境建置通常是他們最痛苦的階段。尤其在『人工管理』的環境中,取得到其他人轉交過來的設備時,因為每個人的開發工具、操作習慣不同,最後通常需要『重灌』整個系統。
問題三:設備閒置,使用時間分配不均
機器可以不休息,但是人總是會有休息時間。以我們的觀察,如果沒有自動進行工作的硬體資源,從購買到汰除的時間裡,至少有一半的時間都是閒置狀態。
舉例來說,當資料科學家取得設備開始,環境建置的時間,資源可以說是閒置狀態,至少不是專心用來進行運算工作。每次的模型訓練結束,到下一次的訓練,也是閒置狀態。因為這個原因,所以我們才會希望客戶能將工作改以 Job 任務來排程,也許不一定能馬上取得資源,但是在有限的資源裡,進行不間斷的運算工作,這樣也算是滿滿的利用了運算資源。
GPU 資源管理與 AI 開發解決方案
為了解決客戶『資源分散、環境建置、設備閒置』的問題,雙子星雲端的 Gemini AI Console 經過不斷地進化,已經成功地幫助眾多的客戶更有效的利用硬體資源。
整合 GPU 資源池
Gemini AI Console 導入了 Kubernetes 容器管理平台,來管理客戶的硬體設備,K8S的好處我就不多說了,最明顯的好處那就是 叢集的擴充變得非常容易,Gemini AI Console 是混合(Public/Private)多雲(Multi-Cloud) 的單一管理平台,在未來雲原生環境的應用上也不是問題。再者,由於容器的應用,對於資料科學家在取得環境的工作上,也比過去實體機/虛擬機還要更加方便與快速。
不過,即使如此,客戶還是遇到了其他的困擾。
導入 K8s 問題:GPU 資源綁定限制
不管是在實體機/虛擬機/容器,都是需要資源與系統的結合,簡單來說就是CPU/MEMORY/DISK/GPU等等資源的使用。如同前面所說的,在AI領域裡,由於運算力的需要,常常會使用 GPU 來加速運算,因此在傳統的作法上,實體機/虛擬機/容器在一開始啟動的時候,就會配好相對應的GPU。這樣一來,配出去一片,總體資源就少了一片,整個管理平台能提供服務的數量很大的被限制住了。
在我們先前的文章「機器學習分享 GPU 的好處」有提到,K8s Default Scheduler 只能夠把整個 GPU 指派給單一容器,因此 AI Console 提供了GPU Partitioning 分割共享 機制,也就是透過獨家的 K8s Scheduler 來達到分割 GPU 提供更多的服務。雖然這個功能也獲得了相當大的好評迴響,但是另一個問題,閒置情況也就更加明顯了。怎麼說呢?這個現象其實要回歸到『開發』環境來說明。
在 AI 領域裡,相當多的人都會使用 Jupyter(Notebook/Lab/Hub)來做開發介面,AI Console 提供使用者很簡單快速的建立這樣的開發環境(容器),當環境建立之後,無論是否使用 GPU Partitioning(分割),都會佔住部分 GPU 資源。因此,當使用者還沒有正式執行模型訓練,或者執行程式時,資源都是屬於閒置狀態。越多的人建立環境,資源就有愈大的可能性是閒置的。
GPU 資源管理進階解決方案:Jupyter to Job
經過雙子星研發部門的努力之後,客戶在模型開發階段,終於可以完全不用佔據 GPU 資源了!只要在 Jupyter 開發介面上,專注於程式碼的撰寫,再搭配 AI Console 專屬的 Jupyter 外掛工具,只需要『點、點、點』,不需要填寫 Job 指令,就可以將 Jupyter 的程式透過 Job 來進行 GPU 環境訓練,一推出就有客戶積極詢問!接下來我就展示一下我們是怎麼做的:
Step1:建立 Jupyter 容器
首先登入系統之後,建立容器服務。選擇 Jupyter To Job 方案來建立 Jupyter開發環境,將會自帶 AI Console 專屬的 Jupyter 外掛功能!
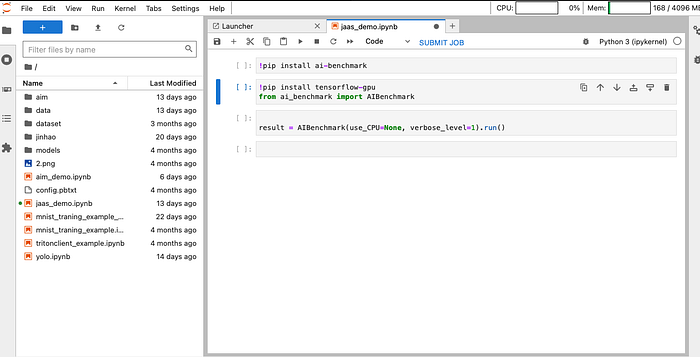
Step2:透過 Jupyter 編輯 AI 網絡模型
Jupyter 容器服務環境建立完成之後,點選進入點即可開啟 JupyterLab。再來就是各位 AI 科學家熟悉的 Jupyter 環境了,只要編輯好 Notebook 內的程式碼即可。我們就以簡單的幾個步驟來測試執行環境的效能,我們選擇的是AI-Benchmark 這個工具。
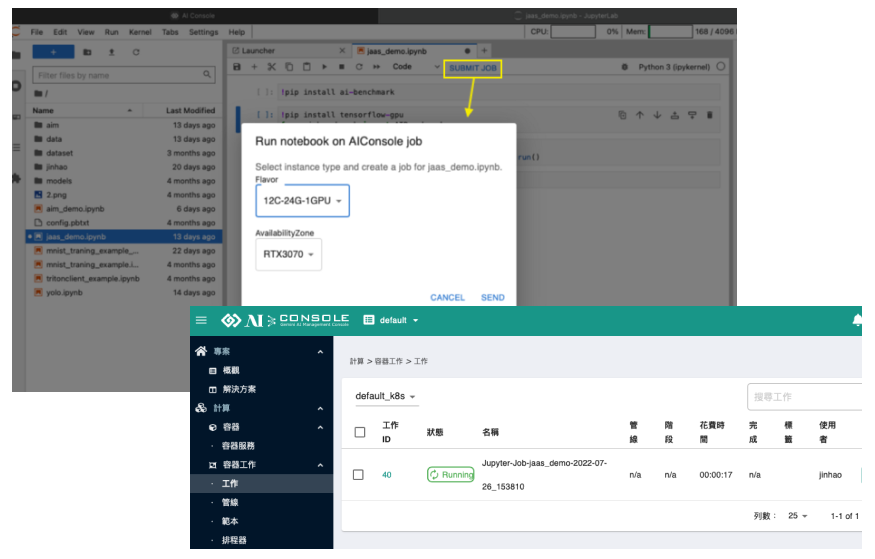
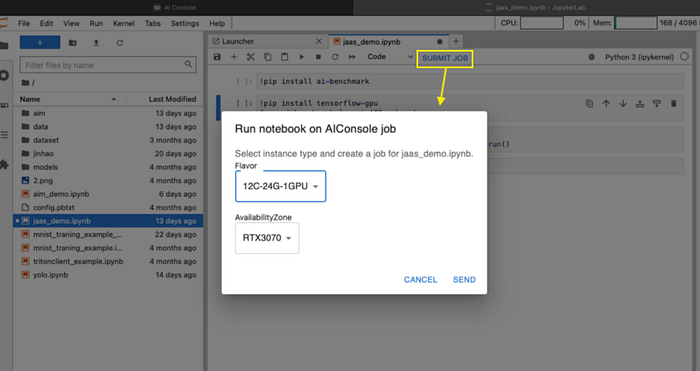
Step3:點選 Submit Job
在上圖右側,上方我們會看到『SUBMIT JOB』這個功能,當程式碼撰寫完畢後,點選這個功能,只需要在彈出的視窗內,選擇要用什麼樣的容器規格(Flavor),以及如果環境中有不同的設備,也可以選擇。最後按下SEND即可。
送出Job成功之後,系統會回覆這次的Job名稱,該名稱最後系統會儲存成新的 Notebook 檔案,這樣的效果就會等同直接執行 Notebook的每一個 Cell程式碼。
Step4:觀看結果
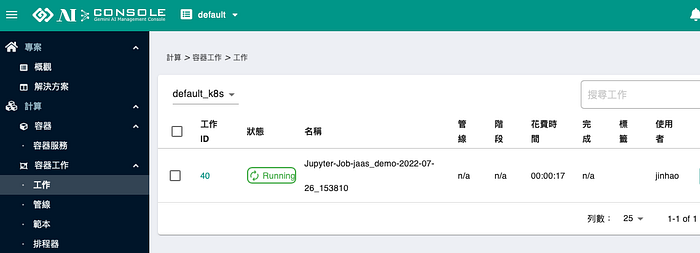
經過上面的步驟,現在系統已經將您的notebook交付給Job在背景執行。現在可以在 AI Console 的 Job 容器工作清單中看到,工作正在執行。
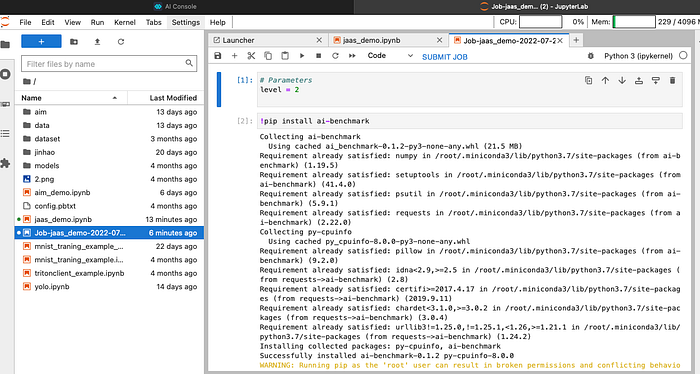
當工作結束後,我們回到Jupyter畫面,這時候,左側會出現這次Job執行後新產生的notebook檔,開啟後,即可看到每個cell執行結果。是不是很方便呢!
透過 Jupyter to Job,冗長的開發階段就可以不再佔據 GPU 資源,等開發到一個段落,即可透過 AI Console 專屬外掛發送 GPU Job 來進行高速訓練,讓您的 GPU 資源達到更有效的利用!
但這樣,GPU Partitioning 就沒有用了嗎?當然不是!GPU Partitioning 非常適合用在不需要太大資源的推論情境上,因為推論情境都很及時,最好隨時都有 GPU 資源 Standby,而 GPU Partitioning 又具有自動化彈性擴增資源的機制,當 GPU 資源有剩餘的情況下,就會自動配發完整的 GPU 給 AI 推論環境,讓你的 AI 服務與 GPU 資源利用達到最完美的平衡!
最後,如果你也想嘗試看看 GPU Partitioning 與 Jupyter to Job,歡迎與我們聯繫,讓我們進一步替你分析與說明,也可預約試用 Gemini AI Console 喔!



