知名晶圓代工廠-大數據AI雲
一、個案概要
知名晶圓代工廠使用了深度學習軟體,在智慧製造的領域衝刺。該公司採用 HPE GPU 伺服器與雙子星雲端 AI Console 建造其 AI 基礎架構,從而為其資料科學家與研究人員提供跨工廠、可擴展的平台,以開發更智能的晶圓生產流程。
Industry
晶圓代工業
Region
台灣
Use Case
- 人工智慧/深度學習
- HPE Apollo 6500 Gen10、HPE ProLiant DL380 Gen10、雙子星雲端 AI Console、 TensorFlow
二、痛點與挑戰
總部位於新竹科學園區的知名晶圓代工廠,其製程機台設備監控方面的經驗,可以追溯到「統計過程控制」(Statistical Process Control,SPC) 方法,該方法使用管制圖的統計方法來監視和控制相關製程,以助於確保製程的高效運行,生產出更多符合規範的產品,並減少返工或報廢造成的浪費。然而,統計過程管制仍有其不足:
- 統計標準差的定義取決與品保/製程工程師的專業度與經驗
- 當生產過程觸發到 OOC (out of control)/OOS (out of spec) 時,代表已經出現製程上的缺失,未能在報廢之前提早發現
- 某些監控需要人力介入判斷 (判斷OOC/OOS是否誤判等等狀況)
智慧製造的關鍵成功因素,就在應用人工智慧與物聯網等技術,持續地優化產線與機台,達到不輸給品保/製程工程師的判斷準確度,又能預防錯誤發生。知名晶圓代工廠為了提高生產效率與製造彈性,同時在品質保證的前提下縮短交期,發展出一套智慧即時監>控與分析的策略,以公司在 AI 與深度學習的專業,迎接晶圓代工業在智慧製造的巨大挑戰。
面臨挑戰
- 傳統的SPC手法,仰賴工程師的經驗與判斷
- 當監控到製程缺失時,代表未能預防浪費發生
- 晶圓代工業必須在效率、彈性、品質與交期之間取得平衡
三、轉型過程
2019年:單一廠區
知名晶圓代工廠的深度學習經驗,始於 2019年,先從單一廠區開始,添購一座 HPE 高階GPU伺服器,用來執行AI模型訓練與推論測試。
而在軟體上,由於當前大多數的AI模型訓練與推論運算所使用的皆是容器環境,因此導入初期,知名晶圓代工廠即委託了雙子星雲>端,提供當前最主流的容器管理工具 — Kubernetes的安裝、建置、維護服務與教育訓練。
晶圓廠的研發人員,即利用此一設備進行模型程式的開發,以及推論程式的部署,初步成功地執行單一廠區的AI導入,獲得成效。
2020年:跨廠區
2020年,鑑於初期導入已有成效,知名晶圓代工廠決定擴大智慧即時監控與分析的範圍至多個廠區的機台,每個廠區都部署了AI推論主機,並且導入雙子星雲端 AI Console 進行多廠區的中央管理。其架構與流程示意如下:
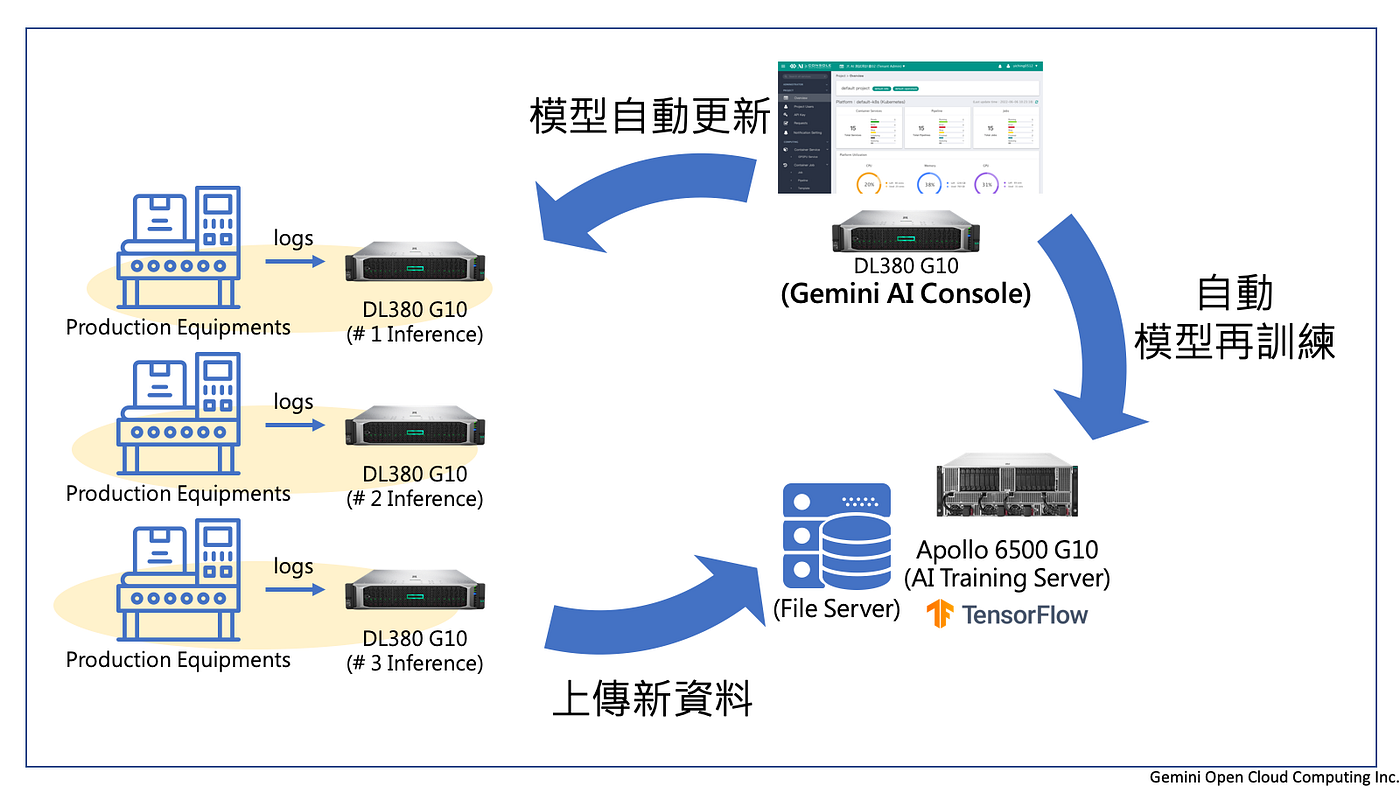
架構設計特色
- 以 HPE Apollo 6500 Gen10 做為模型訓練主機
- 以 HPE ProLiant DL380 Gen10 (包含 GPU) 做為推論主機,部署於各個廠區,進行模型推論;並收集所有機台資訊,送回訓練主機,進行重新訓練,持續改良即時監控的準確率
- 透過雙子星雲端 AI Console,集中管理分散在各個廠區的GPU主機,建立跨廠區的MLOps流程,在推論程式執行之前,自動更新最新版本的模型
四、轉型成果
結合 HPE Apollo 主機和雙子星雲端 AI Console 的機器學習基礎架構,徹底滿足了知名晶圓代工廠的需求:
- 降低人為介入的誤判與節省人力成本
- 更早預測生產即將觸及危險訊號,在問題發生前預先處理問題
- 避免因問題發生而產生不良品與停止生產動作,從而提高產能與良率
知名晶圓代工廠的資料科學家表示:「在雙子星雲端 AI Console 導入之前,我們把資料整理、模型訓練、推論計算皆放置於同一容器中執行,無論是否需要高階GPU卡來加速,GPU卡都被該容器給獨佔了,其他的AI專案無法導入,因此專案的推展速度難以提高。
導入雙子星雲端 AI Console 以後,雙子星雲端協助晶圓廠把資料整理和訓練改以Container Site與Container Job 的工作任務,資料整理不再佔用GPU資源,而在模型訓練結束後,就能釋出GPU卡給其他AI專案,讓GPU卡的使用率大幅提高,也加速了晶圓廠的AI專案進度。
同時,雙子星雲端的客戶成功團隊協助晶圓廠導入其他MLOps 相關工具,例如 DVC、GitLab、Jenkins 等,讓MLOps 流程更加豐富與順暢。
商業轉型
知名晶圓代工廠在智慧即時監控與分析方面取得了突破。透過深度學習技術,知名晶圓廠節省了人力、提高了產能與良率,在晶圓代工智慧製造領域取得了重要地位。如今,資料科學家無需等待,也能有足夠的資源來推廣新的AI專案,以確保晶圓生產的品質。
IT轉型
- 雙子星雲端 AI Console 與客戶成功團隊,協助晶圓廠在模型管理與縮短訓練間隔時間上,取得了突破性的進展
- 模型訓練時間的減少,也代表了晶圓廠的IT投資更有效益,而且資料科學家的生產力也更高