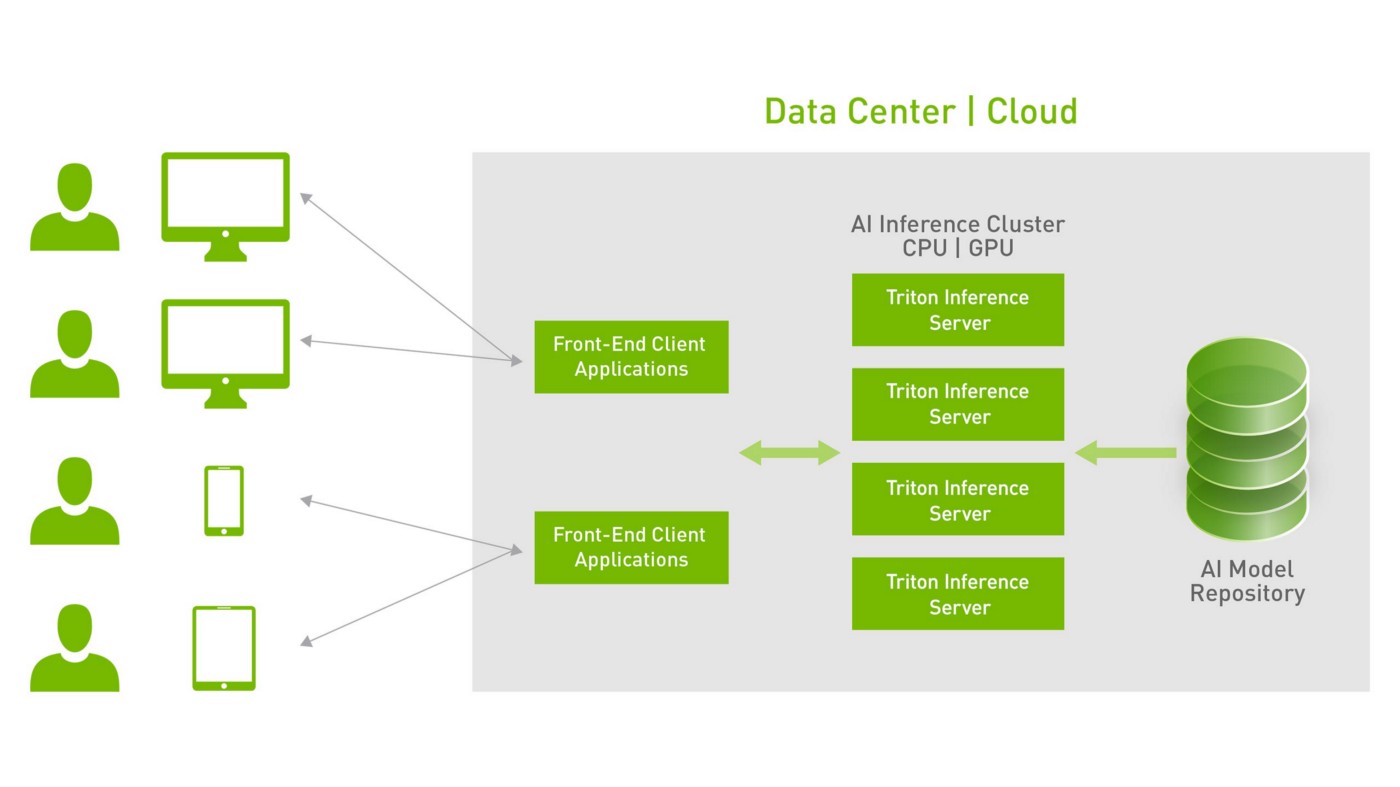
NVIDIA TRITON SERVER 運作架構 (from Nvidia 官網)
Triton 簡介
從人工智慧發展到至今的深度學習,伴隨著技術不斷進步並帶給人們生活更加便利與智能,例如:每天手機 Line上出現的推薦文章、在企業中以深度學習應用在產線上的檢測都拜 AI 所賜,在這些的應用中所用到的服務則稱為推論服務 (Inference),是將 AI 整合至應用程式中最複雜且麻煩的部分。
Nvidia 釋出的一套開源軟體 — 模型推論解決方案 — NVIDIA Triton Inference Server,能夠彈性支援多種 AI framework、低延遲、高吞吐等特性,複雜的Inference 流程交給 Triton 負責,讓開發者可專心於 AI 開發工作。

Triton 架構與範例
Triton 為 Client-Server 架構,Server 端主要功能為模型推論及管理,Client端則為服務請求,將資料傳輸給 Server 端,以獲得推論結果。透過 Triton Client API,自行結合如網頁、手機 APP 等來實現與 Triton Server 的通訊。Triton 支援使用所有的主流框架後端進行推論:TensorFlow、PyTorch、TensorRT、ONNX Runtime,甚至支援以 C++ 和 Python 編寫的自訂後端。

特性
- 支援多種 AI 框架。
- Model 可支援部署在 CPU、GPU 環境中,採用動態批次處理且同時能執行多個 Model,提升了 CPU、GPU 利用率。
- 支援即時、批次和串流推論查詢。
- 在實際使用時,無須中斷應用程式即可於 Triton 中更新模型。
- 提供高傳輸量、低延遲推論品質。
- 支援讓應用程式進行通訊的標準 HTTP/REST 和 gRPC 接口。
- 擁有監控功能,例如:GPU/CPU 使用率、服務延遲等指標。
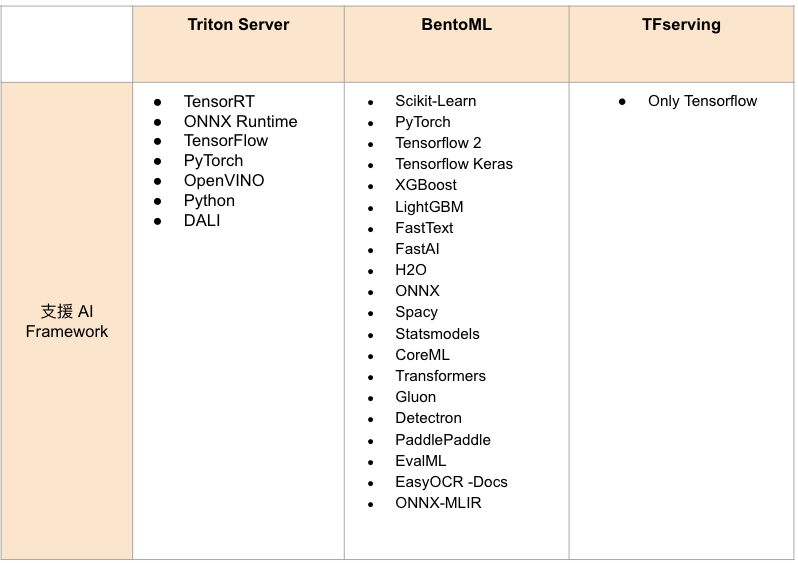
Triton 與其他知名的 Inference 工具之比較
Triton Server 是由 Nvidia 開發的 Inference 解決方案,妥善利用硬體資源而設計的軟體,具備低延遲、高吞吐量的優點,非常適合處理即時、客戶批量的服務請求,是作為 Inference 服務工具的首選。以下為常用的 Inference 工具之比較。

在 Gemini AI Console 上如何使用 Triton
Triton 主要分為兩個部分,Server 端與 Client 端:
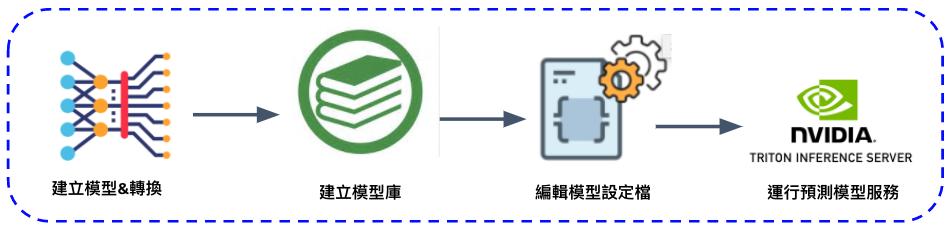
Server端運行流程
Server端主要是搭建 Inference 服務,提供給 Client 請求服務。
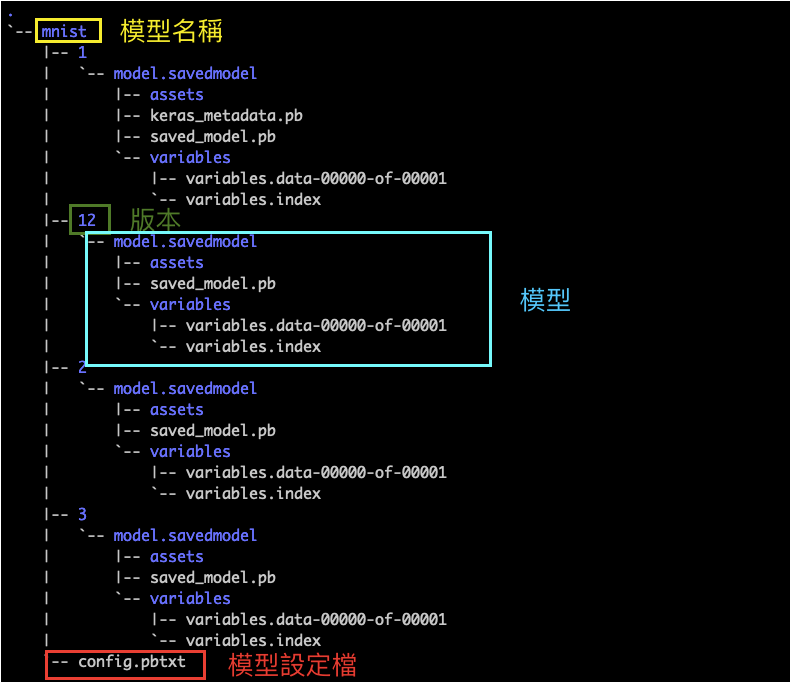
模型庫
模型庫裡可以存放多個模型包,例如 MNIST、Yolo。每個模型包裡會有一個設定檔與多個版本模型。下圖為模型庫架構。
模型設定檔
每個模型包皆須有設定檔,系統會根據設定檔來運行模型,最基本的設定檔由 5 大元素組成:模型名稱、模型框架、Batch Size、輸入及輸出層的資訊、GPU 實例資訊。
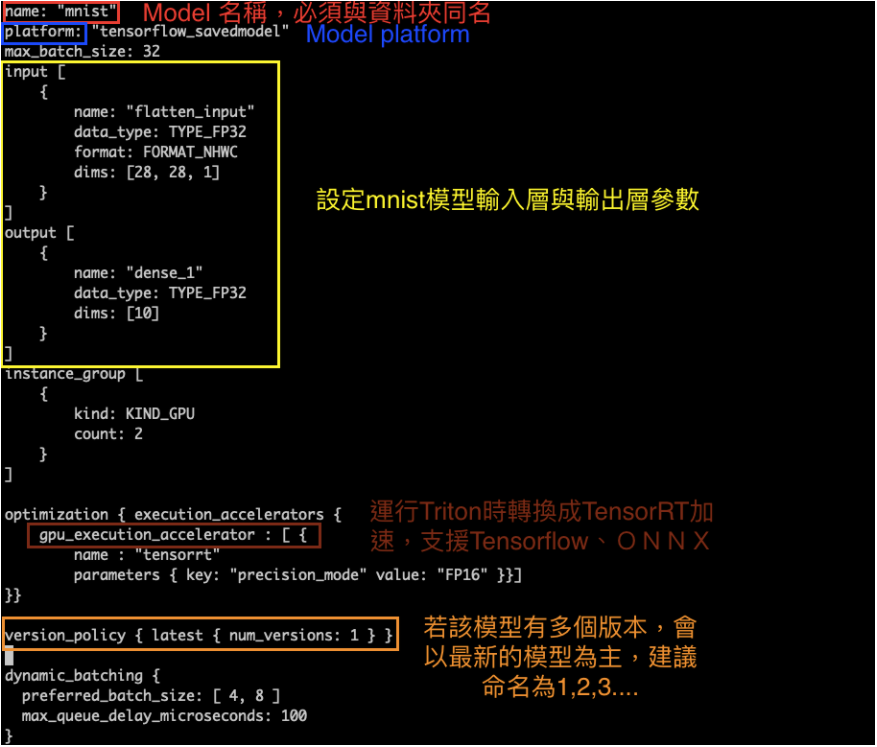
運行 Triton Server — 操作步驟
Gemini AI Console 上已上架 Triton package,因此可直接透過 Gemini AI Console 上提供應用程式清單,讓使用者直接選取創立。
點擊 Gemini AI Console 中的 Triton

User input parameters
- Flavor:配置運算資源給予此應用程式,由於 Triton Server 需要有 GPU 資源,因此需要配置 GPU 運算資源,否則會建立失敗。
- Command(範例):
tritonserver --model-store=/models --backend-config=tensorflow,version=2 --backend-config=tensorflow,allow-soft-placement=0 --model-control-mode=poll --repository-poll-secs=5
- Storage:將存放在 NFS 上的 Model 檔掛載到容器中,讓 Triton server 讀取。
- Share Directory:輸入 NFS 上 Model 路徑。
- Mount Directory:將 NFS 上的 Model 掛載到 Triton 容器中,填入Command 指定的 Model 位置。
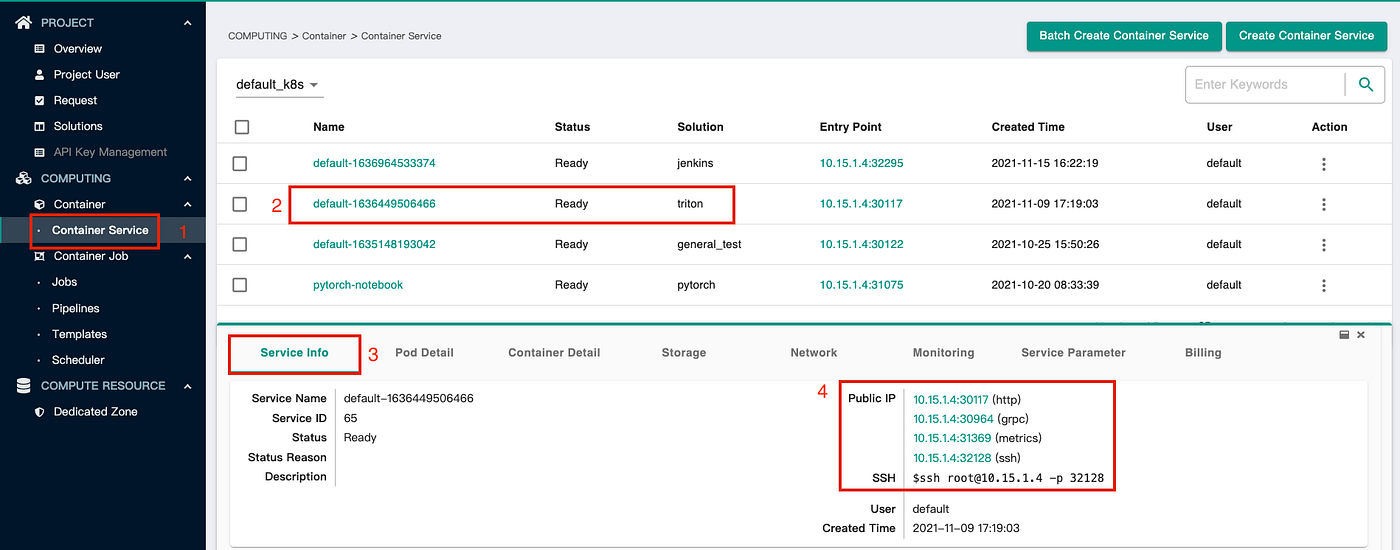
- 當 Triton Server 建立成功後,可以透過 RestAPI 檢查服務是否正常,在 AI Console 點擊步驟為:Container service -> 點選建立的 Triton Server 服務 -> Service Info -> UI 顯示的 Public IP
# Metrics Service:8002 port
curl localhost:8002/metrics
# Health check, Http Service:8000 port
curl -v localhost:8000/v2/health/ready
# Model Status
curl localhost:8000/v2/models[/${MODEL_NAME}[/versions/${MODEL_VERSION}]]/stats
Client 運行流程
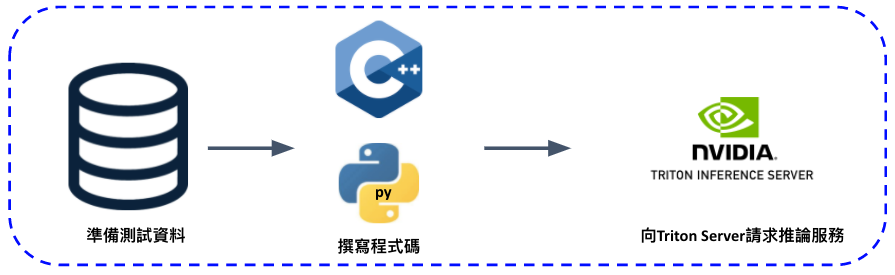
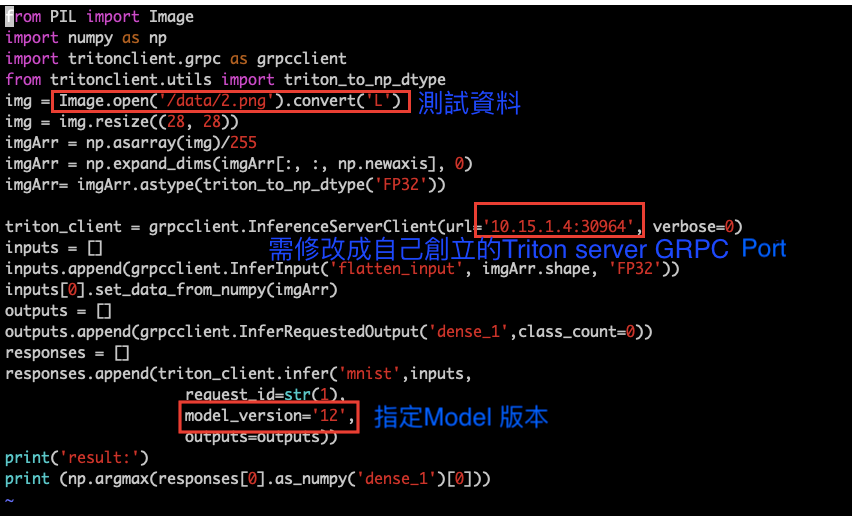
建置好 Triton Server 服務後,客戶端該怎麼使用 Triton Server 服務呢? 方法有兩種:可透過 Python 或 C++語言來編寫自訂義的服務請求。範例中,我們拿 Mnist 手寫數字資料作為舉例,選擇 Python 語言撰寫服務請求。
範例程式架構:主要分成三大部分
- 前處理:此部分主要將資料進行預測前的所有處理,如影像解碼、維度轉換、訊號處理等等。
- 與 Triton server 溝通:指定將推論的模型資訊,透過 HTTP 或 GRPC 跟Server 溝通。
- 後處理:得到資料推論後的結果進行後處理,如儲存檔案、訊息整理、結果呈現等等。
範例程式
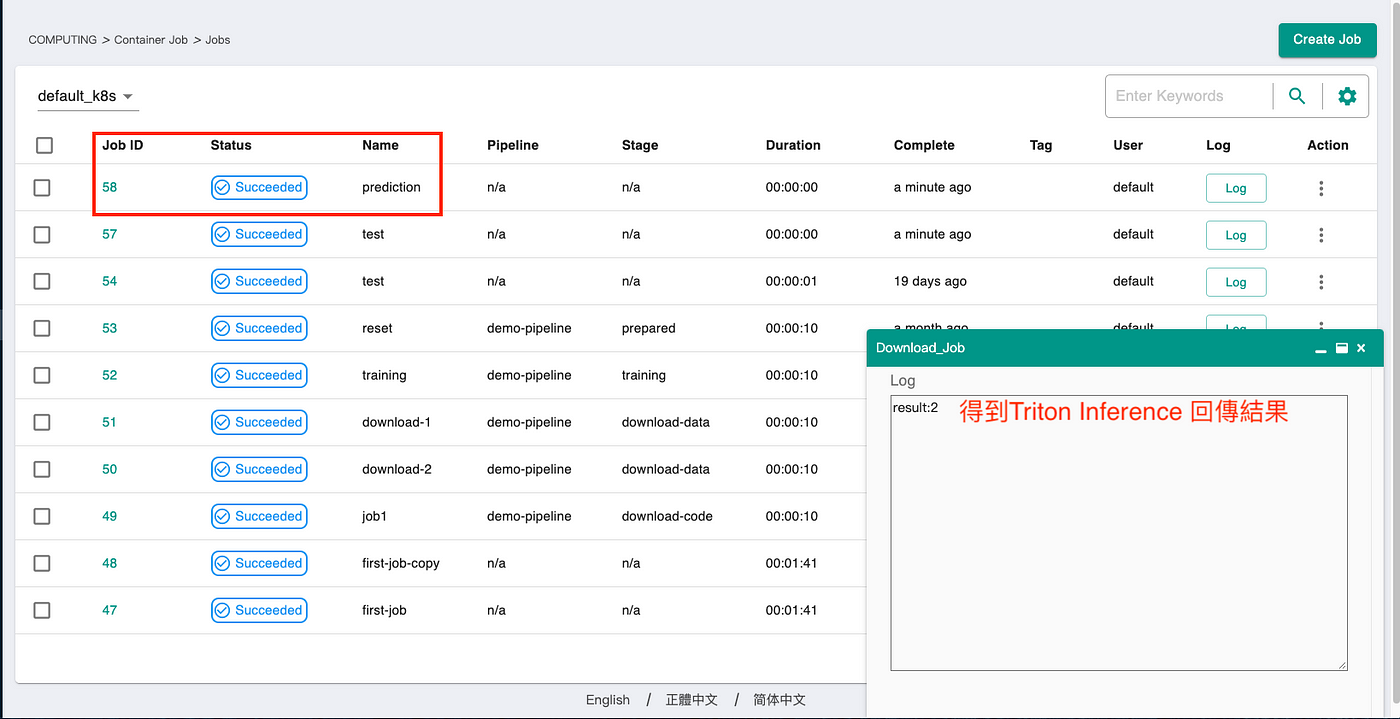
透過 AI Console Job 服務取得 Inference 結果
在範例中以數字 2 作為測試資料,透過 AI Console 平台 Job 功能執行撰寫好的 Python 檔進行預測服務。透過 Job 功能執行的好處是:執行完畢後,將馬上釋放運算資源,不會空佔資源而導致真正需要使用時,沒有資源可使用問題。
執行的 Shell 語法
sudo docker run -d --name <Container Name> -v <Data Path>:/data nvcr.io/nvidia/tritonserver:21.02-py3-sdk bash -c '<Client Code>'

結論
在科技快速發展的時代,許多強大軟體如雨後春筍般一個個出現,對許多DE(Data Engineer) 來說是非常便利的,但要管理與建制硬體、系統基礎建設是個”痛點“,若導入 Gemini AI Console 後,DE 只需要專注於 MLOps 開發、聚焦於 Model 調教,進而讓 Inference 品質能做到更好。
References:
- https://developer.nvidia.com/nvidia-triton-inference-server
- https://developer.nvidia.com/blog/simplifying-and-scaling-inference-serving-with-triton-2-3/




