Well-known wafer foundry - Big Data / AI Cloud
1. Case Summary
Well-known wafer foundry use deep learning software to sprint in the field of smart manufacturing. The company uses HPE GPU servers and Gemini Open Cloud AI Console to build its AI infrastructure to provide data scientists and researchers with a cross-factory, scalable platform to develop smarter IC fabrication pipeline.
Industry
Manufacture of Semi-conductors
Region
Taiwan
Use Case
- Artificial Intelligence/Deep Learning
- HPE Apollo 6500 Gen10、HPE ProLiant DL380 Gen10、Gemini Open Cloud AI Console、 TensorFlow
2. Pain points and challenges
A well-known wafer foundry headquartered in the Hsinchu Science Park, its experience in fabrication equipment monitoring can be traced back to the Statistical Process Control (SPC) method, which uses the statistical method of control charts to monitor and control the relevant manufacturing process helps ensure the efficient operation of the manufacturing process, produces more products that meet the specifications, and reduces waste caused by rework or scrap. However, the statistical process control still has its shortcomings:
- The definition of statistical standard deviation depends on the experience of professionalism and quality assurance/process engineers.
- When the production process is triggered to OOC (out of control)/OOS (out of spec), it means that there has been a defect in the process, and it has not been found early before it is scrapped.
- Some monitoring requires human intervention to judge (judge whether OOC/OOS is misjudgment, etc.)
The key success factors for smart manufacturing lies on the application of technologies such as artificial intelligence and the Internet of Things, and continuous optimization of production pipelines and machines, to achieve judgment accuracy similar to quality assurance/process engineers, and to prevent errors.
In order to improve production efficiency and manufacturing flexibility, and at the same time shorten the delivery time under the premise of quality assurance, the well-known wafer foundry have developed a set of smart real-time monitoring and analysis strategies to meet the huge challenge in smart manufacturing.
Challenge
- Traditional SPC methods rely on the experience and judgment of engineers
- When the monitoring process is deficiency, it means that the waste has not been prevented.
- The wafer foundry industry must strike a balance between efficiency, flexibility, quality and delivery
3. Transformation process
2019: Single Factory
The deep learning experience of a well-known wafer foundry began in 2019. It started with a single factory area and purchased an HPE high-end GPU server to perform AI model training and inference testing.
For the software part, since most of the current AI model training and inference computing use container environments, the well-known wafer foundry commissioned Gemini Open Cloud to provide the current most mainstream container management tool — Kubernetes. Including installation, construction, maintenance services and education and training.
The R&D of the fab used this equipment to develop the model and deployment inference program. Successfully implemented the AI import of a single factory area, and achieved results.
2020:Cross Factories
In 2020, in view of the initial results, the well-known foundry decided to expand the scope of intelligent real-time monitoring and analysis to machines in cross factories. Each factory has deployed an AI inference host and imported the Gemini Cloud AI Console for central administration. The structure and process are as follows:
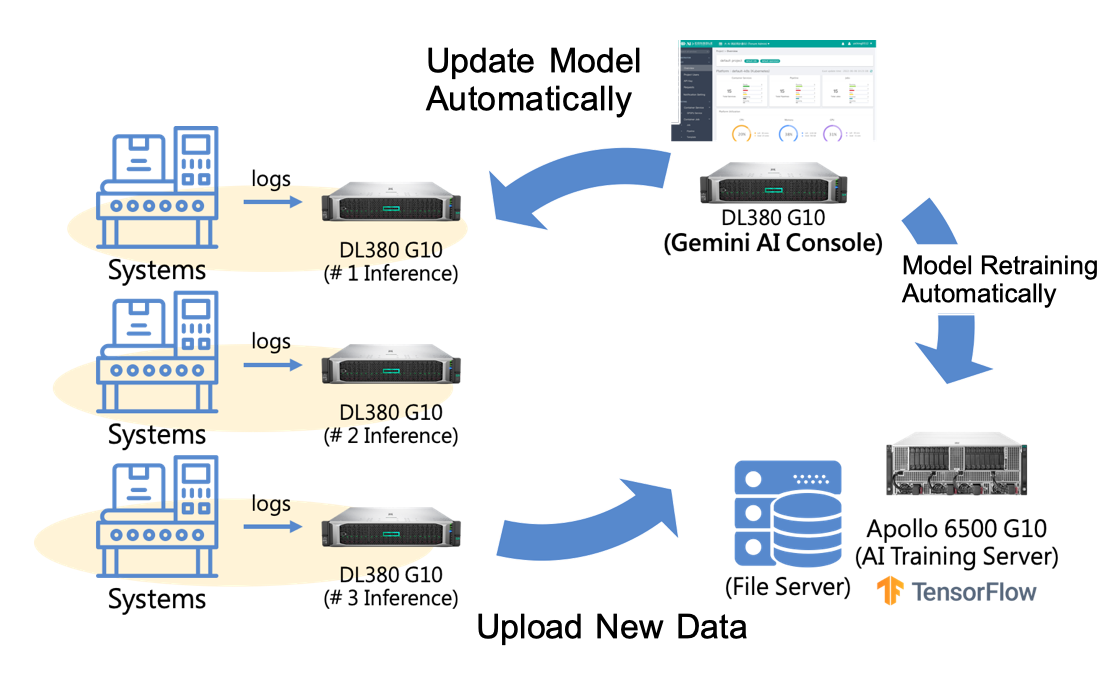
Architecture Design
- Use HPE Apollo 6500 Gen10 as the model training host
- Use HPE ProLiant DL380 Gen10 (including GPU) as the inference host and deploy it in factories to perform model inference; collect all machine information and send it back to the training host for retraining to continuously improve the accuracy of real-time monitoring
- Through the Gemini Cloud AI Console, centrally manage the GPU hosts scattered in each factory, establish a cross-factory MLOps process, and automatically update the latest version of the model before the inference program executed.
4. Results
The machine learning infrastructure combined with HPE Apollo host and Gemini Open Cloud AI Console fully meets the needs of well-known foundries:
- Reduce the misjudgment caused by human intervention and save labor costs
- Predict production dangerous signals eariler to solve problems before occurs
- Avoid producing defective products and stopping production due to problems, thereby increasing productivity and yield
A data scientist from the well-known wafer foundry said: “Before the import of the Gemini Open Cloud AI Console, we put data collection, model training, and inference in the same container for execution, regardless of whether high-end GPU cards are needed for acceleration. All the GPU resources are exclusively by this container, and other AI projects cannot be imported, so it is difficult to increase the speed of project development.
After importing the Gemini Open Cloud AI Console, Gemini Open Cloud assisted the fab to change the data collection and training to Container Site and Container Job tasks. The data collection no longer takes up GPU resources, and after the model training is over, you can release GPU cards to other AI projects. Which has greatly increased the utilization rate of GPU cards and accelerated the progress of AI projects in fabs.
At the same time, the customer success team of Gemini Open Cloud assisted the fab to import other MLOps related tools, such as DVC, GitLab, Jenkins, to make the MLOps process richer and smoother.
Business transformation
Well-known foundries have made breakthroughs in intelligent real-time monitoring and analysis. Through deep learning technology, well-known fabs have saved manpower, increased production capacity and yield, and achieved an important position in the field of foundry smart manufacturing. Nowadays, data scientists do not need to wait, and they can also have enough resources to promote new AI projects to ensure the quality of wafer production.
IT transformation
- Gemini Cloud AI Console and customer success team assisted the fab to achieve breakthrough progress in model management and shortening the training interval
- Reducing the model training time, which also means that IT investment of the fab is more effective, and the productivity of data scientist is higher